
Comparison of the Performance of Whisper ASR and Human on Transcription Task of whispered Mandarin Speech
Overview: This research compares the performance of the WHISPER automatic speech recognition (ASR) system and human transcription in transcribing whispered Mandarin speech. Results show that WHISPER performs consistently across text types, it is outperformed by human transcription.
Methods: Python, Paired samples t-test
Abstract
The emergence of automatic speech recognition (ASR) is an important branch in the field of human-computer interaction, which provides material for further text processing and offers extensive support for speech and text technologies. Its effective operation relies heavily on the clarity, consistency and predictability of the speech signal. Therefore, dealing with varying speech quality is the key and difficult point for ASR systems. This paper will focus on performance comparison of the current leading Whisper ASR system and Human Speech Recognition (HSR) in transcribing whispered speech, with Mandarin selected as the target language. Considering the fact that Mandarin is a tonal language and the tones play a crucial role in conveying meaning, the challenges posed by this feature to the ASR system will be more significant and worth studying. This study attempts to investigate the strengths and weaknesses of Whisper and manual transcription by comparing the results of 16 sentences (comprising 8 daily utterances and 8 literary recitations) to provide insights to identify areas for potential improvement. The experimental results shows that the Whisper ASR system performed uniformly across different text categories, but it was evidently outperformed by human, particularly with daily utterances. This suggest that Whisper also needs to improve its ability to generate transcription results with context and to adapt the model to the acoustic characteristics of whispered Mandarin speech.
Key words: Whisper ASR, Human transcription, whispered Mandarin speech, performance comparison
1. Introduction and Background
Automatic Speech Recognition (ASR) systems, pivotal in contemporary technology, convert spoken language into text. Their applications span various domains, from voice-activated assistants to transcription services. One notable ASR system is WHISPER, which is trained on diverse and extensive multilingual datasets, so is capable of recognizing and processing various speech patterns, accents, and dialects and is known for its adaptability and accuracy. These systems, traditionally optimized for normal speech, face unique challenges when dealing with whispered speech, a variant significantly different in acoustic properties.
Mandarin as a tonal language relies heavily on pitch variations to convey meaning. Tones in Mandarin are crucial for distinguishing between words that would otherwise be homophones. The absence of vocal fold vibration leads to a considerable reduction in speech energy and speaking rate, a significant factor in speech recognition technologies and human perception.
Many previous studies have focused on the special acoustic features of whispered Mandarin speech compared to normal speech. In addition to the obvious absence of f0, studies by Chang Charles and Yao Yao (2007) emphasizes the shrinking but still significant differences in duration and intensity among the four lexical tones in Mandarin. Complementing these findings, research by Gang Lv and Heming Zhao (2010) have demonstrated that whispered Mandarin vowels exhibit a notable upward shift in formant frequency, expanded and nearly constant formant bandwidths, much lower gain and flatter spectrum. With regard to consonants in whispered Mandarin, key findings from Xu et al. (2022) shows that consonants tend to have longer durations and varied intensities, with nasals and semivowels being notably lower in intensity and others showed a notably increase. Fricatives and affricatives perceived largely unchanged spectrum with a narrower distinction in duration among them.
In addition to this, Gao and Esling’s (2003) use Laryngoscopic endoscopy to demonstrate the physiological aspects of whispered mandarin. It shows that the height of the larynx primarily dictates pitch shifting, serving as a substitute for the vocal folds vibration, rising tonal contours correlates with rising larynx, and the sphincteric opening correlates with the production of noise in whisper, which controls tone intensity, thus playing a role similar to the loudness in phonated tones.
Given all the unique properties of whispered speech compared to phonated speech, along with the current sparse corpus of whisper Mandarin available as training material, it is reasonable to assume that WHISPER’s performance will be impaired, as ASR systems largely depend on the acoustic properties of speech, which undergo significant changes in whispering. Assessment of normal speech recognition is familiar topic, in this paper I will design experiments to compare the performance of the leading ASR system Whisper with human speech recognition (HSR).
Hypothesis. Since humans rely more on contextual cues and previous language experience than the asr system, this may give them an advantage in understanding whispered speech with unique acoustic properties. We therefore hypothesize that there is a significant difference in performance between WHISPER and HSR, and that human transcription outperforms WHISPER. Similarly, since daily phrases are used more than literary texts, it can be hypothesized that transcription of daily texts performs significantly better than literary texts.
By investigating the acoustic properties of whispered Mandarin and reviewing related studies, the complexities involved in recognizing and transcribing whispered speech can be better understood. Combined with the performance comparisons and results analyzed in this study, these may contribute to the improvement of speech recognition in specific domains. Moreover, improving the recognition rate of whispered speech is also beneficial to help patients with vocal cord vibration deficiency to communicate with others and to solve the problem of speech transcription in some special scenarios, thus it is also an application-worthy problem.
2. Method
2.1 Data Collection:
Stimuli preparation. Considering the low intelligibility of isolated monosyllables in whispered Mandarin (Anthony Holbrook and Hsiao-Tung Lu, 1969) this study utilizes complete sentences as experimental material to enhance intelligibility. In the pre-experiments, the transcription of slow, clear whispered recordings was very effective, especially for daily utterances, and both Whisper ASR and human were able to achieve character error rates (CER) approaching zero. So, the difficulty of the transcription task was increased by increasing the speed of speech to amplify the difference.
Since gender has also been shown to affect ASR recognition (Marcely Zanon Boito et al. 2022), 16 recordings from one female speaker aged 24 were selected as experimental material, which also ensures a consistent whispering level and speaking rate across all recordings.
The 16 sentences contain characters ranging from 19-34, with an average length of x characters. The first eight sentences are daily sentences and the last eight sentences are prose extracts. The first eight sentences are set with whispered homophones that are difficult to distinguish and require a combination of contexts to transcribe correctly.
All stimuli were recorded as mono recordings with resolution 44100hz on Praat using computer microphone.
Participants Selection. Transcribers includes 6 native Mandarin speakers, 4 female and 2 male, 22-28 years.
Data collection. With respect to ASR systems, the whisper-large-v3 released in November 2023 were chosen to represent the leading performance of ASR. All recordings were transcribed through the model on Colab. Similarly, all recordings were given to 6 participants and their results were recorded and processed.
Pre-processing. All HSR results are saved in the Transcription.txt, and the preprocessed results after removing non-characters including punctuations and blank spaces are saved in Transcription.csv. Afterward data analysis was based on the Transcription.csv file.
2.3 Evaluation matrix and data analysis
The Character Error Rate (CER) will be the metric for assessing transcription performance. CER is defined as the percentage ratio of the minimum number of insertions (i), substitutions (s) and deletions (d) of characters that are required to obtain the gold answer and the total number of characters (n):
CER = (i + s + d) / nCER of the transcription results from 6 participants were averaged as the performance of the human transcription. CER calculations were done using python package jiwer.
Paired t-test was conducted as a measure of whether there was a significant difference between the ASR and HSR performance. Furthermore, transcription performance of 8 daily utterances and 8 literary recitations were also compared to assessed the effect of text category. A simple t-test was conducted to see whether there was a significant difference between the 2 text categories regarding ASR and HSR performance. Data analysis was done in python.
3. Results
3.1. Basic statistics of data and Normality test
All of the CER data was stored in a CER_Results.csv file, and we will be focusing on the analysis and comparison of the WHISPER and HSR columns of data in the following. Here HSR performance is represented by the mean performance of all participants.
| Count | Mean | Std | p | |
| WHISPER | 16 | 0.2591 | 0.1537 | 0.9864 |
| HSR | 16 | 0.1487 | 0.1208 | 0.0326 |
Table 1: Basic information of WHISPER and HSR performance
According to the basic information of CER, ASR model Whisper has higher Mean and higher Std of CER than HSR, which indicates a lower accuracy of transcription of whispered Mandarin and more erratic performance for multiple sentences. This tentatively suggests that humans may be more adept at transcription and comprehension of whispered Mandarin speech.
Apart from that, HSR data do not follow a normal distribution (p<0.05), which may affect the validity of parametric tests because many of them (e.g., t-tests) assume normal distribution of the data. There are two approaches to address this case,: (1) applying data transformations to make the data more consistent with a normal distribution, and (2) using nonparametric methods such as the Mann-Whitney U test or the Wilcoxon rank sum test, which do not rely on the assumption of a normal distribution. In response to method 1, not all data can necessarily be transformed to achieve a normal distribution, and this transformation may introduce new issues or inaccuracies that change the nature of the data relationship. After applying some data transformations it was found that no satisfactory normal distribution could be achieved, so non-parametric tests was adopted.
In this context, the Wilcoxon Signed-Rank Test was first employed to compare the performance difference between CERs derived from pairs of sentences using WHISPER and HSR to compare the transcription performance between WHISPER and HSR. The Mann-Whitney U Test was then used to compare the transcription performance of WHISPER and HSR between daily utterances and literary text, respectively.
3.2. Comparison of WHISPER and Human transcription performance
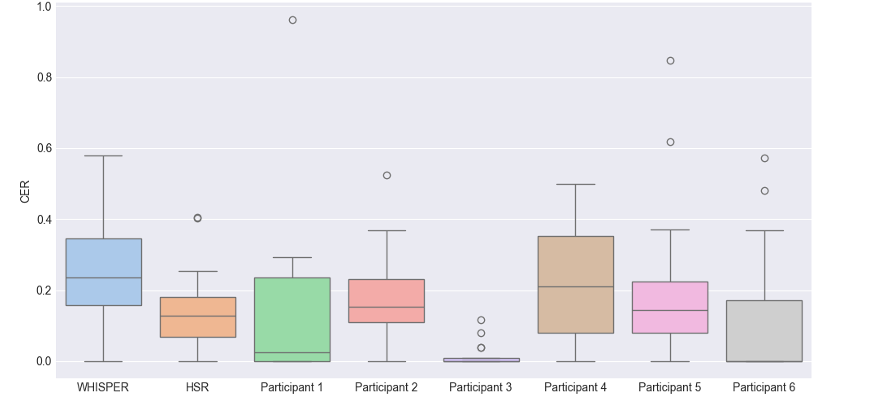
Figure 1: CER Comparison: WHISPER, HSR, Participants
The figure above shows the character error rate (CER) of WHISPER and human transcribers (HSR and Participants 1 to 6) for the transcription of 16 sentences. A lower CER indicates fewer errors in transcription and better performance.
WHISPER had a wide distribution of CERs, with a minimum value of 0, a maximum value close to 0.6, and a median around 0.25. The boxplots for WHISPER showed large variability, implying that its performance fluctuates widely from sentence to sentence. The CERs for HSR were generally lower than those for WHISPER, suggesting that the performance of the human transcriber was generally superior.
For individuals, participants 1, 3, and 6 achieved zero error in most cases, which may indicate a high level of mastery of the transcription task. For the CER close to 1 that appeared in participant 1 and participant 5, the transcriber did not understand the entire sentence, so the answer was mostly blank, with only a few characters. The difference in CER between participants indicates that performance on the transcription task may differ between individuals due to experience, familiarity, or other factors. This was verified in my callback with participant 3, who had memorized the prose due to her former translation test preparation.
Generally speaking, human transcribers performed better and with less variability than WHISPER, probably because humans are better at using contextual information and linguistic knowledge to recognize whispers.
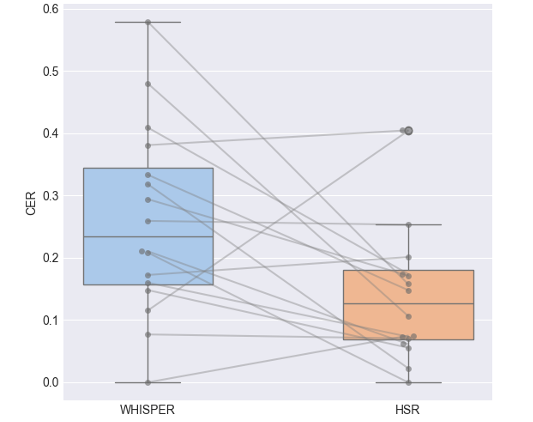
Figure 2: CER Comparison with Paired Sentences
The boxplots with paired sentences above show that HSR obtains significantly lower CERs than WHISPER for 12 of the 16 sentences in the group. Of the 4 groups of sentences where WHISPER performs better, only the 10th sentence has a CER that is significantly greater for WHISPER than HSR. the remaining 4th group of sentences WHISPER achieves an accuracy of 0. The 4th group of sentences has a CER of 0. 0.03 for the 12th sentence and 0.02 for the 13th. (Explain each sentence specifically)
Statistically, according to Wilcoxon Signed-Rank Test result p-value is 0.02496, which indicates that overall HSR is more accurate than WHISPER in transcription task of whispered Mandarin speech.
3.3. Comparison of transcription performance of different text category
The sentences for the experimental design consisted of eight daily utterance and eight literary excerpts, and this section compares the transcription results of WHISPER and HSR of the two genres respectively, from the figure and using the Mann-Whitney U test.
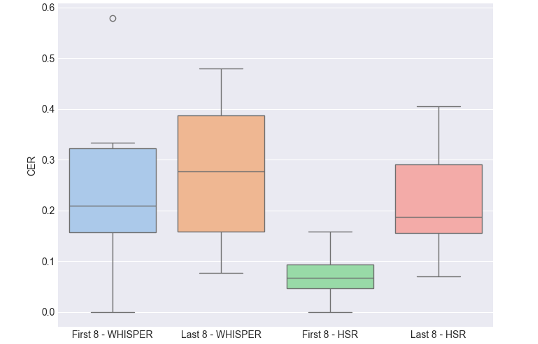
Figure 3: CER Comparison: First 8 vs. Last 8 Sentences for WHISPER and HSR
For WHISPER, the median CERs for the first and last eight sentences were close to each other, and the size and shape of the box plots were similar, which means that there was no significant difference in the performance of the ASR system on daily phrases and literary excerpts. For HSR, the CERs for the first eight sentences were significantly lower than those for the last eight sentences, and the box plots showed less variability, suggesting that human transcribers perform significantly better on daily utterances than on literary excerpts.
The p-value of the Mann-Whitney U test was used to determine whether there was a statistically significant difference between the medians of two independent samples. For WHISPER, the p-value is 0.7209, much higher than 0.05, which indicates that there is insufficient evidence for a difference in ASR performance between everyday language and literary excerpts.
For HSR, the p-value is 0.0047, much less than 0.05, so there exists a significant difference in transcription performance between human transcribers on everyday language and literary excerpts. This is consistent with the intuitive conclusions we draw from Fig.
4. Conclusion
The aim of this study was to explore the ability of the Whisper ASR system and human transcribers (HSR) in transcribing whispered Mandarin speech, focusing on a comparative evaluation across 16 sentences comprising both daily utterances and literary excerpts.
The Character Error Rate (CER) served as the primary metric for assessing transcription accuracy. Whisper ASR exhibited higher mean CER values, indicating a lower overall accuracy in the transcription of whispered Mandarin speech compared to human transcribers.
The Whisper ASR system’s performance did not show a significant difference when transcribing daily utterances versus literary excerpts. However, the human transcribers demonstrated superior performance, particularly with daily utterances, which can be attributed to their ability to leverage contextual cues and linguistic knowledge more effectively than the current ASR systems.
Overall, the human performed better than the ASR system. This highlights the ability of the human transcriber to deal with the nuances of whispered Mandarin, especially with confusing homophones, as well as the ability to understand literary texts, which remains a challenge for the ASR system.
5. Discussion
The results of the study show that while ASR systems like Whisper have made great progress in general speech recognition, there is still a considerable gap in their ability to process whispered speech.
Further advances in ASR technology will be necessary to approach the flexibility and comprehension skills demonstrated by human transcriptionists. This should focus on improving the ability to interpret contextual information and adjust transcription results accordingly, which is crucial for the accurate transcription of whispered Mandarin speech with absent acoustic cues.
In addition, attention should also be focused on the problem of “homophone” confusion in whispered Mandarin. Future research directions in this area could focus on exploring advanced algorithms that are able to distinguish subtle pitch changes in the absence of typical articulations. For example, Spectrum Sparse-Based feature extraction research by Chen Xuegin et al. (2016) has proposed spectrum sparse-based approaches for feature extraction that have shown promise in improving whispered speech recognition.
Research on adapting the structure of ASR models to recognize different speech types, such as children’s speech investigated by Rishabh Jain et al. (2023) also reminds us of the importance of model fine-tuning.
As well as most importantly, the effectiveness of an ASR system depends on its training dataset, so the inclusion of a variety of speech samples (including whispers) is crucial to the development of a robust and versatile ASR system. In this regard, in addition to a Mandarin whisper database proposed by Pei Xuan Lee et al. in 2016, there has not yet been rich research on the subject. However, some recent articles, e.g. by Zhaofeng Lin et al. (2023) have also proposed some methods for building a corpus of WHISPERED speech using a normal corpus with specific processing, which might compensate for the shortage of data in this direction.
By addressing these challenges, we aim to close the gap between human and machine speech recognition capabilities, paving the way for ASR systems to accurately transcribe Mandarin whispered speech, enhance communication for people with vocal cord impairments, and provide reliable transcription in specialized scenarios.
References
https://github.com/openai/whisper?tab=readme-ov-file whisper-openai
Boito, Marcely Zanon, Laurent Besacier, Natalia Tomashenko, and Yannick Estève. “A Study of Gender Impact in Self-Supervised Models for Speech-to-Text Systems.” arXiv, July 5, 2022. https://doi.org/10.48550/arXiv.2204.01397.
Chang, Charles B, and Yao Yao. “Tone Production in Whispered Mandarin.” UC Berkeley Phonology Lab Annual Reports 3 (2007). https://doi.org/10.5070/P71581Q7QR.
Gao, Man, and John H Esling. “Articulatory Features of Tones in Whispered Chinese,” 2003.
Holbrook, Anthony, and Hsiao‐Tung Lu. “A Study of Intelligibility in Whispered Chinese.” Speech Monographs 36, no. 4 (November 1, 1969): 464–66. https://doi.org/10.1080/03637756909375641.
Jain, Rishabh, Andrei Barcovschi, Mariam Yiwere, Peter Corcoran, and Horia Cucu. “Adaptation of Whisper Models to Child Speech Recognition.” arXiv, July 24, 2023. https://doi.org/10.48550/arXiv.2307.13008.
Lee, P.X., D. Wee, Hilary Toh, Boon Pang Lim, Nancy Chen, and Bin Ma. “A Whispered Mandarin Corpus for Speech Technology Applications.” Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, January 1, 2014, 1598–1602.
Lin, Zhaofeng, Tanvina Patel, and Odette Scharenborg. “Improving Whispered Speech Recognition Performance Using Pseudo-Whispered Based Data Augmentation.” arXiv.org, November 9, 2023. https://arxiv.org/abs/2311.05179v1.
Lv, Gang, and Heming Zhao. “Acoustic Analyses of Whispered Mandarin.” In 2010 3rd International Congress on Image and Signal Processing, 7:3486–89, 2010. https://doi.org/10.1109/CISP.2010.5646755.
Xu, Min, Jing Shao, Hongwei Ding, and Lan Wang. “Acoustic-Perceptual Correlates of Whispered Mandarin Consonants.” In 2022 13th International Symposium on Chinese Spoken Language Processing (ISCSLP), 195–99, 2022. https://doi.org/10.1109/ISCSLP57327.2022.10037817.
Xueqin, Chen, Zhao Heming, and Fan Xiaohe. “Performance Analysis of Mandarin Whispered Speech Recognition Based on Normal Speech Training Model.” In 2016 Sixth International Conference on Information Science and Technology (ICIST), 548–51, 2016. https://doi.org/10.1109/ICIST.2016.7483475.